AOISAKURA 日記
2004-06-27 またエアコンつけたまま寝てたし...
_ [web][java] CyberNeko HTML Parser
前から、HTMLの構造をXMLに変換するライブラリないかねぇとか思ってたら、普通にあったんですね...。今月のJava Worldで、HTMLパーサーの特集があって、それで初めて知りました。
で、その中でapache.orgの中の人が作っているということで、apache関係のXMLのAPIと相性いいかもとか思ってCyberNeko HTML Parserを使いはじめました。はてさて、どうなることやら。
_ [gimp] gimpでお絵描き

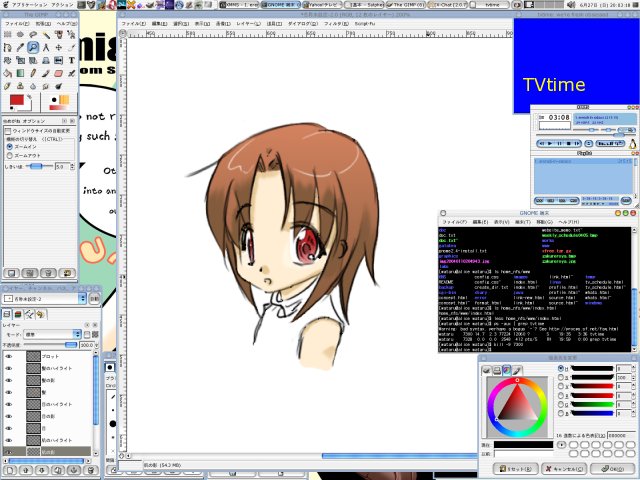
何も考えず2時間、相変わらず(っていうか何もしてないからなんやけども)ゴミが乗るので掃除が大変、塗りをするときも問題が発生するから辛い辛い...。
使ってて思ったのが、レイヤーをグループ化とかできたら便利かもしれないなぁ。
左側の画像は、作業環境です。久しぶりにスクリーンショットを撮ってみた。ちなみに、画面右上はテレビの画面です。ヤクルト対巨人を見ながら作業してました。
_ [tdiary] tDiary 2.0.0へ
ずっとカテゴリ分けをしようと思っていて、いざやろうと思ったらなんとtDiary1.4.xではカテゴリは使えない事が発覚!というわけで、バージョンアップしようと思ったら、新しい安定版2.0.0が出ていたので、さっそく移行してみました。いろいろいじり中です。
最初カテゴリ分けをしようとすると日記の更新の際にエラーが起きていましたが、どうもデータ系式が1.4のままだとカテゴリを生かせないみたいでした。データを2.0の系式に直したら完了。
_ [camera] デジカメ購入計画
臨時収入が入ったので、そろそろ買おうと思うんですが、今迷っているのが、CASIOのEXILIM EX-S20とEX-Z3なんですよ。S20は新品で、Z3は中古で23000円なんで、どっちにしようかなぁとぐるぐる迷っております。日が昇までには決めたいなぁ。
とか思っていたけど、今デジカメを買うと遊んでしまいそうなので、7/16が過ぎるまでは手を出さないことにやっぱりします。今のところEX-Z3が優勢
2005-06-27 残業残業残業...
_ [book] 2005 オープンソース最前線
KeN's GNU/Linux Diary経由。なんだかすごいメンバーが並んでる。あ、石井先生発見。
_ [tdiary] amazonの書影が取得できない
amazon側の画像情報に変更があったのかしら。とりあえずwgetを使ってrefer、セッション情報無しで画像は取得できているので、なんとかなるだろう。今はなんとかしてる時間無いー。
_ [link][computer][programming] @IT - スタンドアロン方式とリアルタイム性能、データ処理技法の地政学とWebアプリケーション開発を支援するプラグイン
2006-06-27 原稿バタバタ
2009-06-27 休出
_ [book][programming] 買った本 - Unix/Linux プログラミングとか
とりあえず買う予定だったので買った感がいなめない...。当分は積ん読。